

هیجانانگیز است که سیستمها قادر به یادگیری از داده باشند، الگوها را شناسایی کنند و با کمترین میزان دخالت انسان به تصمیمگیری بپردازند. یادگیری عمیق به نوعی از یادگیری ماشین اطلاق میشود که از شبکههای عصبی استفاده میکند. این نوع یادگیری به سرعت در حال تبدیل شدن به ابزاری برای حل مسائل مختلف محاسباتی است. از جمله این مسائل میتوان به طبقهبندی اشیاء و سیستمهای توصیهگر اشاره کرد. با این حال، بکارگیری شبکههای عصبی آموزش دیده در حوزهها و خدمات گوناگون میتواند چالشهایی را برای مدیران زیرساختها به همراه داشته باشد. چالشهایی همچون چارچوبهای گوناگون، زیرساختهای بیاستفاده و نبود مراحل اجرایی استاندارد میتواند زمینه را برای شکست پروژههای هوش مصنوعی مهیا کند. پست حاضر بر آن است تا راهکارهای غلبه بر این چالشها را بررسی کرده و از مدل های یادگیری عمیق در مرکز داده یا ابر استفاده کند.
عموماً، ما توسعهدهندگان نرمافزار با دانشمندان داده و فناوری اطلاعات همکاری میکنیم تا مدلهای هوش مصنوعی ساخته شوند. دانشمندان داده از چارچوبهای ویژهای برای آموزشِ مدل های یادگیری عمیق یا ماشین در کاربردهای مختلف استفاده میکنند. ما مدلِ آموزش یافته را به صورت یکپارچه در قالب نرمافزار ارائه میدهیم تا مسئله حل شود. در اقدام بعد، تیم عملیات فناوری اطلاعات، نرمافزار را در مرکز داده یا ابر اجرا و مدیریت میکند.

مدل های یادگیری عمیق
دو چالش عمده در ساخت مدل های یادگیری عمیق
۱. باید از مدلها و چارچوبهای مختلفی که به توسعه الگوریتم یادگیری میافزایند، پشتیبانی کنیم. باید مسئله گردش کار را نیز مد نظر قرار داد. دانشمندان داده بر پایه دادهها و الگوریتمهای جدید به توسعه مدلهای جدید میپردازند و ما باید به طور دائم تولید را بهروزرسانی کنیم.
۲. اگر از کارت گرافیک NVIDIA برای حصول سطوح عملکردی فوقالعاده استفاده کنیم، باید به چند نکته توجه کنیم. اولاً، کارتهای گرافیک منابع محاسبه قدرتمندی هستند و شاید اجرای یک مدل در هر کارت گرافیکی بهینه نباشد. اجرای چند مدل در یک کارت گرافیک باعث نخواهد شد آنها به صورت خودکار همزمان اجرا شوند.
پس چه کار میتوان کرد؟ بیایید ببینیم چگونه میتوان از نرمافزاری مثل سرور استنتاجTensorRT برای رویارویی با این چالشها استفاده کرد. امکان دانلود سرور استنتاج TensorRT از NVIDIA NGC registry یا به عنوان کد منبع باز از GitHub وجود دارد.
TENSORRT INFERENCE SERVER
سرور استنتاج TensorRT با بهرهگیری از ویژگیهای زیر، استفاده از شبکههای عصبی آموزشدیده را آسان میکند:
پشتیبانی از چند چارچوب مدل: میتوان چالش اول را با استفاده از منبع مدل سرور استنتاجTensorRT بررسی کرد که نوعی محل ذخیره به شمار میآید. بنابراین، امکان توسعه مدل از چارچوبهایی مثل تنسورفلو، TensorRT، ONNX، PyTorch، Caffe، Chainer، MXNet و غیره وجود دارد. سِرور میتواند مدلهای ساخته شده در همه این چارچوبها را به کار گیرد. با اجرای inference server container در سرور CPU یا GPU، همه مدلها از منبع در حافظه بارگذاری میشود. نرمافزار از یک API استفاده میکند تا سرور inference را برای اجرای عملیات استنتاج بر روی مدل فراخوانی کند. اگر تعداد مدلهایی که نمیتوانند در حافظه جای گیرند زیاد باشد، این امکان وجود دارد که منبع را به چند منبع کوچکتر تقسیم کنیم و نمونههای مختلفی از سرور استنتاج TensorRT را به اجرا در آوریم. میتوان مدلها را به راحتی با تغییر منبع مدل بهروزرسانی، اضافه یا حذف کرد؛ حتی زمانی که سرور inference و نرمافزارمان در حال اجرا باشند.
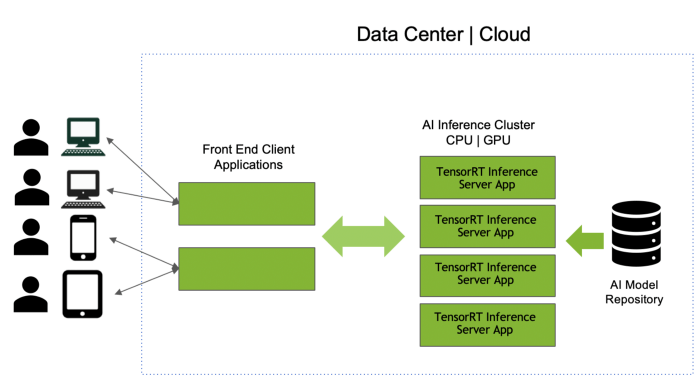
مدل های یادگیری عمیق
افزایش حداکثریِ استفاده از کارت گرافیک: اکنون که با موفقیت سرور inference و نرمافزار را به اجرا در آوردهایم، میتوانیم چالش دوم را نیز از پیش رو برداریم. استفاده از کارت گرافیک غالباً یکی از شاخصهای عملکردی بسیار مهم برای مدیران زیرساخت است. TensorRT Inference Server میتواند به طور همزمان چندین مدل را روی GPU زمانبندی کند. این سرور به طور خودکار استفاده از GPU را به صورت حداکثری افزایش میدهد. بنابراین، ما به عنوان افراد توسعهدهنده نیازی به اجرای روشهای خاص نداریم. به جای اینکه یک مدل در هر سرور به کار برده شود، عملیات IT، کانتینر یکسان سرور استنتاجTensorRT را در همه سرورها اجرا میکند. از آنجایی که مدلهای متعددی در این عملیات مورد پشتیبانی قرار میگیرند، GPU استفاده شده و سرورها تعادل بیشتری در مقایسه با تنها یک مدل در هر سناریوی سرور خواهند داشت.
فعال سازی بلادرنگ و استنتاج دستهای: دو نوع استنتاج وجود دارد. اگر نرمافزار بخواهد به صورت بلادرنگ به نیازهای کاربران پاسخ دهد، باید استنتاج نیز به صورت بلادرنگ انجام شود. از آنجا که تاخیر همیشه مسئله نگرانکنندهای بوده است، امکان قرار دادنِ درخواستها در صف وجود ندارد و نمیتواند در کنار سایر درخواستها دسته بندی شود. از سوی دیگر، اگر هیچ الزام بلادرنگی وجود نداشته باشد، این امکان در اختیار کاربر گذاشته میشود تا این درخواست را در کنار سایر درخواستها بچیند و استفاده از GPU و بازدهی آن را افزایش دهد. در هنگام توسعه نرمافزار باید به درک خوبی از نرمافزارهای بلادرنگ دست یابیم. سرور استنتاجTensorRT پارامتری دارد که میتواند با آن یک آستانه تاخیر برای نرمافزارهای بلادرنگ لحاظ کند. این پارامتر از دستهبندی پویا نیز پشتیبانی میکند. این پارامتر میتواند با یک مقدار غیرصفر مقدار دهی شود تا درخواست های دسته ای را پیاده سازی کند. باید عملیات IT را به منظور اطمینان حاصل کردن از درستیِ پارامترها اجرا کرد.
استنتاج در CPU و GPU و دستۀ غیرهمگن: بسیاری از سازمانها از GPU عمدتاً برای آموزش استفاده میکنند. استنتاج در سرورهای عادی CPU اجرا میشود. هرچند اجرای عملیات استنتاج در GPU باعث افزایش قابل توجه سرعت کار میشود اما اینکار نیاز به انعطافپذیری بالای مدل دارد. سرور استنتاج TensorRT هر دو استنتاج CPU و GPU را پشتیبانی میکند. بگذارید این موضوع را بررسی کنیم که چطور میتوان از استنتاج CPU به GPU تغییر مسیر داد:
۱. دستۀ فعلیمان فقط مجموعهای از سرورهای CPU است که همگی سرور استنتاجTensorRT اجرا میکنند.
۲. سرورهای GPU را به دسته معرفی میکنیم و نرمافزار سرور استنتاجTensorRT را در این سرورها اجرا کنیم.
۳. مدلهای شتاب دهنده GPU را به منبع مدل اضافه میکنیم.
۴. با استفاده از فایل پیکربندی، ما سرور استنتاج TensorRT را بر روی این سرورها ایجاد میکنیم تا از GPU برای عملیات استنتاج استفاده کند.
۵. میتوانیم سرورهای CPU را دسته کنار بگذاریم یا هر دو را در حالت غیرهمگن به کار ببریم.
۶. هیچ تغییر کدی در نرمافزار برای فراخوانی سرور استنتاج TensorRT مورد نیاز نیست.
یکپارچهسازی با زیرساخت DevOps: نکته آخر بیشتر میتواند به درد تیمهای فناوری اطلاعات بخورد. آیا سازمانِ شما از DevOps تبعیت میکند؟ آن دسته از افرادی که با این عبارت آشنایی ندارند، بدانند که DevOps به مجموعهای از فرایندها و فعالیتها اطلاق میشود که چرخه توسعه و بکارگیریِ نرمافزار را کاهش میدهد. سازمانهایی که به استفاده از DevOps روی میآورند، از کانتینرها برای بستهبندی نرمافزارهایشان استفاده میکنند. سرورTensorRT یک کانتینر Docker است. تیم فناوری اطلاعات میتواند از Kubernetes برای مدیریت و مقیاسدهی استفاده کند. این امکان نیز وجود دارد که سرور استنتاج را به بخشی از خطوط لوله Kubeflow به منظور دستیابی به یک گردشکار هوش مصنوعی انتها به انتها تبدیل کنیم.
بسیار آسان است که سرور استنتاج TensorRT را بوسیله تنظیم فایل پیکربندی و تجمیع کتابخانهها، با برنامهمان تجمیع کنیم.
بکارگیریِ شبکههای عصبیِ آموزشدیده میتواند چالشهایی را به همراه داشته باشد اما هدفمان در مقاله حاضر این بود که نکات و سرنخهایی به کاربران دهیم تا فرایند بکارگیری این شبکهها به آسانی انجام شود و استفاده از مدل های یادگیری عمیق به سهولت انجام گیرد. لطفا نظرات و پیشنهادات خود را در بخش زیر وارد کنید. به ما بگویید که با چه چالشهایی در هنگام اجرای عملیات استنتاج روبرو شدید و چگونه این چالشها را از پیش رو برداشتید.
منبع: hooshio.com
 فیلترهای زیبایی دیجیتال به رنگ گرایی تداوم میبخشند
فیلترهای زیبایی دیجیتال به رنگ گرایی تداوم میبخشند نوآوری هوش مصنوعی در استفاده از ماشین فروش خودکار
نوآوری هوش مصنوعی در استفاده از ماشین فروش خودکار