

مقاله حاضر بر آن است تا یادگیری عصبی ساماندهی شده در کتابخانه تنسورفلو را معرفی کرده و جزئیات آن را تشریح کند. «TensorFlow» یک چارچوب ساده است که افراد حرفهای و تازهکار میتوانند از آن برای آموزش
شبکههای عصبی با سیگنالهای ساماندهی شده استفاده کنند. یادگیری عصبی ساماندهی شده (NSL) میتواند برای ایجاد مدلهای دقیق و قوی در حوزههای بصری، درک زبانی و پیشبینی استفاده شود.
دادههای ساماندهی شده کاربردهای مفیدی در خیلی از فعالیتهای یادگیری ماشین دارند. این دادهها حاوی اطلاعات منطقی غنی در میان سایر نمونهها هستند. برای مثال، مدلسازیِ شبکههای رونگاشت ، استنتاج گراف دانشو استدلال در خصوص ساختار زبانیِ جملات، و یادگیری اثرانگشتهای مولکولی همگی مستلزم مدلی است که از خروجیهای ساماندهی شده اقدام به یادگیری کند.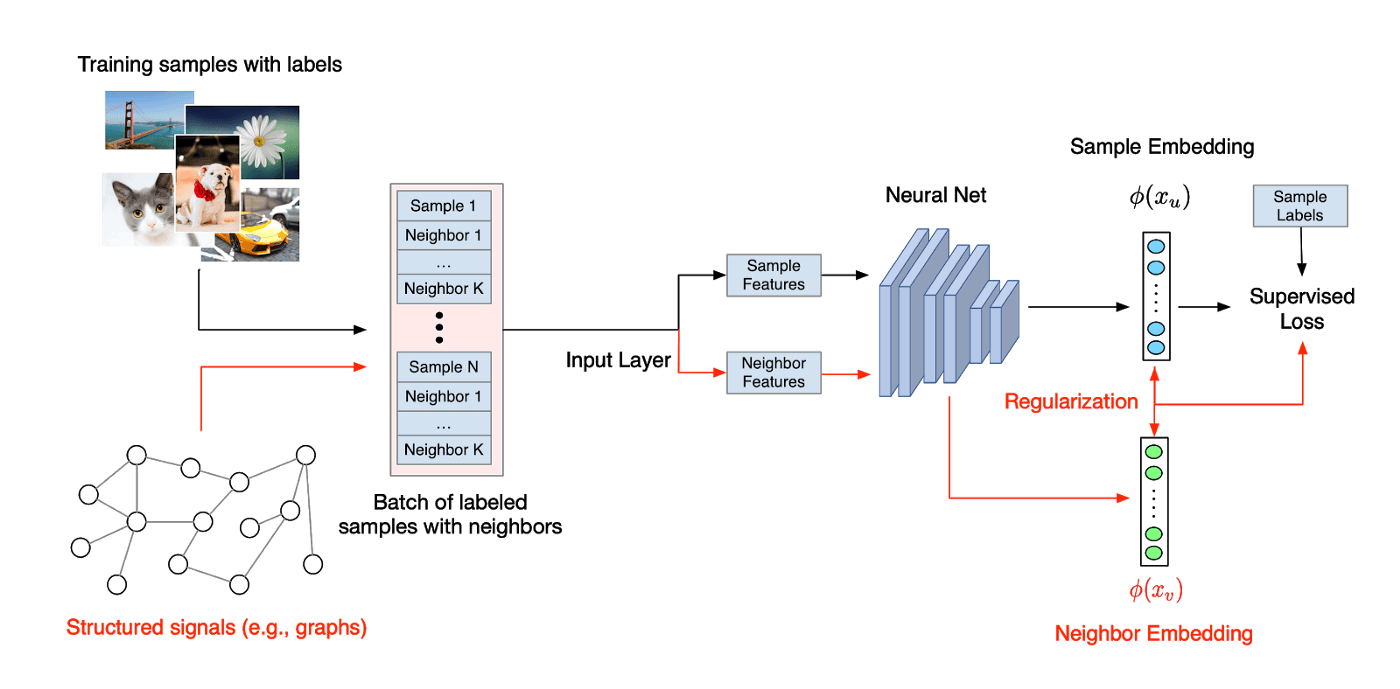 این ساختارها میتوانند به صورت صریح (به عنوان مثال بوسیله یک گراف) و یا به صورت ضمنی (به عنوان مثال بوسیله داده های متضاد) ارائه شوند. استفاده از سیگنالهای ساماندهی شده در طول آموزش این فرصت را به طراحان و توسعهدهندگان میدهد که دقت مدل بالاتری داشته باشند؛ به ویژه زمانی که میزان دادههای برچسب زده شده نسبتاً کم باشد. آموزش با سیگنالهای ساماندهی شده باعث ایجاد مدلهای مقاوم تر میشود. این شیوهها کاربرد وسیعی در گوگل دارند و نقش بزرگی در بهبود عملکرد مدل ایفا میکنند؛ مثلیادگیری تعبیه شده معنایی تصاویر .
این ساختارها میتوانند به صورت صریح (به عنوان مثال بوسیله یک گراف) و یا به صورت ضمنی (به عنوان مثال بوسیله داده های متضاد) ارائه شوند. استفاده از سیگنالهای ساماندهی شده در طول آموزش این فرصت را به طراحان و توسعهدهندگان میدهد که دقت مدل بالاتری داشته باشند؛ به ویژه زمانی که میزان دادههای برچسب زده شده نسبتاً کم باشد. آموزش با سیگنالهای ساماندهی شده باعث ایجاد مدلهای مقاوم تر میشود. این شیوهها کاربرد وسیعی در گوگل دارند و نقش بزرگی در بهبود عملکرد مدل ایفا میکنند؛ مثلیادگیری تعبیه شده معنایی تصاویر .
یادگیری عصبی ساماندهی شده (NSL) یک چارچوب منبع باز برای آموزش شبکههای عصبی عمیق با سیگنالهای ساماندهی شده است. این چارچوب «یادگیری عصبی گرافی» را اجرا میکند. این نوع یادگیری به توسعهدهندگان امکانِ آموزش شبکههای عصبی با استفاده از گرافی را میدهد. این گرافها میتوانند از منابع مختلفی به دست بیایند؛ از جمله این گرافها میتوان به گرافهای «Knowledge»، دادههای آرشیو پزشکی، دادههای ژنومی یا روابط چندوجهی اشاره کرد. همچنین NSL از یادگیری تخاصمی استفاده میکند که طی آن، ساختارِ میان نمونههای ورودی به صورت پویا و با استفاده از آشفتگی تخاصمی ساخته میشوند. NSL این فرصت را به کاربران «TensorFlow» میدهد تا به راحتی از سیگنالهای ساماندهی شدۀ گوناگون برای آموزش شبکههای عصبی استفاده کنند. این نوع یادگیری در سناریوهای یادگیری مختلف قابل استفاده میباشد.
یادگیری عصبی ساماندهی شده (NSL) چگونه کار میکند؟

در یادگیری عصبی ساماندهی شده (NSL)، سیگنالهای ساماندهی شده (که صراحتاً در قالب گراف تعریف میشوند یا به صورت ضمنی در قالب نمونههای تخاصمی استفاده میشوند) برای عادیسازیِ آموزش شبکههای عصبی به کار برده میشوند. لذا مدل تحت اجبار قرار میگیرد تا پیشبینیهای دقیق را یاد بگیرد (بوسیله کمینه کردن supervised loss). در همین حین، شباهت میان ورودیهای یک ساختار را نیز حفظ میکند (بوسیله کمینه کردن neighbor loss). این روش، یک روش متداول است و میتواند در معماریهای هر شبکه عصبی دلخواه از قبیل شبکههای عصبی پیشرو ، شبکههای عصبی پیچشیو شبکههای عصبی بازگشتیبکار رود.
ساخت مدل با یادگیری عصبی ساماندهی شده (NSL)
ساخت مدل به کمک یادگیری عصبی ساماندهی شده (NSL) برای بهرهمندی از سیگنالهای ساماندهی شده به کار سادهای تبدیل شده است. با توجه به گراف و نمونههای آموزش، NSL ابزاری برای پردازش و ادغام این نمونهها در قالب «TFRecords» فراهم میکند. به مثال زیر توجه کنید:
|
۱ ۲ ۳ ۴ ۵ |
python pack_nbrs.py --max_nbrs=۵ \ labeled_data.tfr \ unlabeled_data.tfr \ graph.tsv \ merged_examples.tfr |
در وهله بعد، چارچوب NSL از API برای مصرف نمونههای پردازش شده استفاده کرده و عادیسازیِ گراف را مقدور میسازد. بگذارید نگاهی به نمونه کُد داشته باشیم:
|
۱ ۲ ۳ ۴ ۵ ۶ ۷ ۸ ۹ |
import neural_structured_learning as nsl# Create a custom model — sequential, functional, or subclass. base_model = tf.keras.Sequential(…)# Wrap the custom model with graph regularization. graph_config = nsl.configs.GraphRegConfig( neighbor_config=nsl.configs.GraphNeighborConfig(max_neighbors=۱)) graph_model = nsl.keras.GraphRegularization(base_model, graph_config)# Compile, train, and evaluate. graph_model.compile(optimizer=’adam’, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’]) graph_model.fit(train_dataset, epochs=۵) graph_model.evaluate(test_dataset) |
ما با کمتر از پنج خط اضافی (از جمله بخش کامنت) به یک مدل عصبی دست یافتیم که از سیگنالهای گراف در طول آموزش استفاده میکند. از دید تجربی، استفاده از ساختار گرافی این امکان را به مدلها میدهد تا بدون کاهش دقت و با دادههای برچسبگذاری شده کمتری به آموزش بپردازند.
اگر ساختار صریحی در کار نباشد، چه باید کرد؟
اگر ساختارهای صریح (مثل گراف) وجود نداشته باشند، چه رویکردی باید در پیش گرفت؟ چارچوبِ NSL ابزارهایی را در اختیار توسعهدهندگان میگذارد تا گرافهایی را از دادههای خام بسازند. در ضمن، چارچوب NSL با فراهم آوردنِ API زمینه را برای استنتاج نمونههای تخاصمی در قالب سیگنالهای ساماندهی شدۀ ضمنی مهیا میکند. نمونههای تخاصمی به صورت تعامدی برای گیج کردن مدل ساخته میشوند؛ آموزش با چنین نمونههایی معمولاً به مدلهایی ختم میشود که در مقابل آشفتگیهای اندک ورودی، عملکرد قوی و خوبی از خود نشان میدهند. در نمونه کُد زیر میبینیم که NSL چگونه امکانِ آموزش با نمونههای تخاصمی را فراهم میکند:
|
۱ ۲ ۳ ۴ ۵ ۶ ۷ ۸ |
import neural_structured_learning as nsl# Create a base model — sequential, functional, or subclass. model = tf.keras.Sequential(…)# Wrap the model with adversarial regularization. adv_config = nsl.configs.make_adv_reg_config(multiplier=۰.۲, adv_step_size=۰.۰۵) adv_model = nsl.keras.AdversarialRegularization(model, adv_config=adv_config)# Compile, train, and evaluate. adv_model.compile(optimizer=’adam’, loss=’sparse_categorical_crossentropy’, metrics=[‘accuracy’]) adv_model.fit({‘feature’: x_train, ‘label’: y_train}, epochs=۵) adv_model.evaluate({‘feature’: x_test, ‘label’: y_test}) |
ما با کمتر از پنج خط اضافی (از جمله بخش کامنت) به یک مدل عصبی دست یافتیم که با نمونههای تخاصمی آموزش دیده و یک ساختار ضمنی ارائه میکند. از دید تجربی، مدلهای آموزش داده شده بدون نمونههای تخاصمی دقت خیلی پایینی دارند.
منبع: hooshio.com
 فیلترهای زیبایی دیجیتال به رنگ گرایی تداوم میبخشند
فیلترهای زیبایی دیجیتال به رنگ گرایی تداوم میبخشند